在这个故事中, we will explore LangChain’s capabilities for question-answering based on a set of documents. We will describe a simple example of an HR application which scans a set of files with CVs in a folder and asks ChatGPT 3.全球最大的博彩平台候选人的5个问题.
我们使用了LangChain v0.0.190年在这里.
这里问的问题/说明是:
求职者的名字是什么?
这个候选人的专业是什么?
请提取所有超链接.
How many years of experience does this candidate have as a mobile developer?
简历中提到了哪些大学?
This simple HR application is embedded in a Web服务器 (using FastAPI with uvicorn) which displays the answers to these questions as a simple webpage.
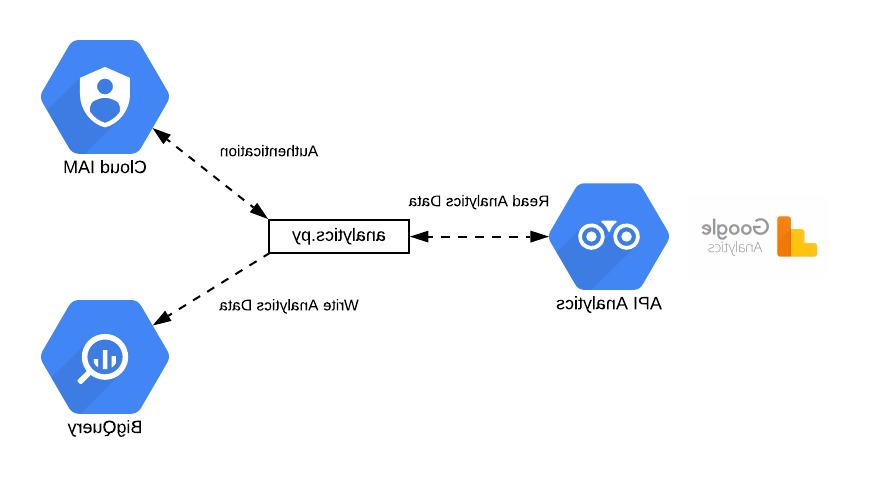
LangChain文档处理能力
LangChain 具有多个文档处理链:
的 的东西 链 includes a document into its question (prompt) context and exposes the question (prompt) to the LLM.
这张图描绘了 的东西 来自Lang链文档的文档链:
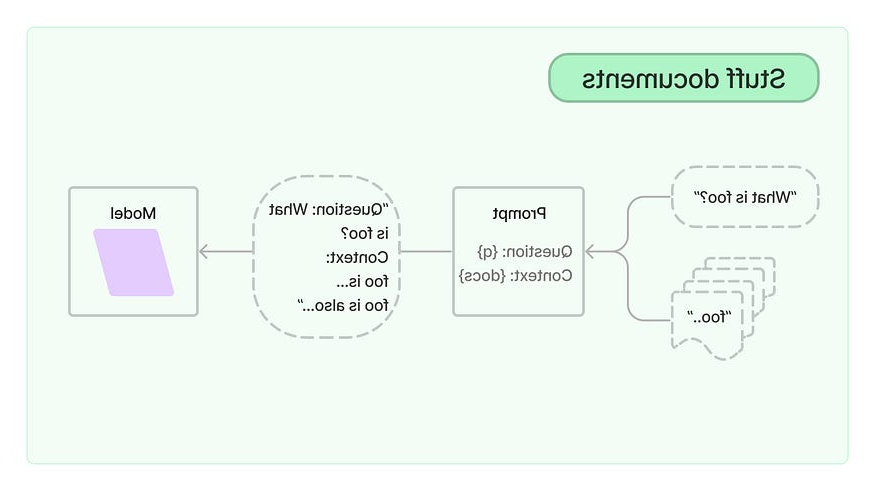
应用程序流
在我们的HR应用程序中有两个工作流:
- the first workflow (QA Creation Process) creates the question and answer list for each specific candidate
- the second one is about getting a web request, converting it to HTML and sending a response back
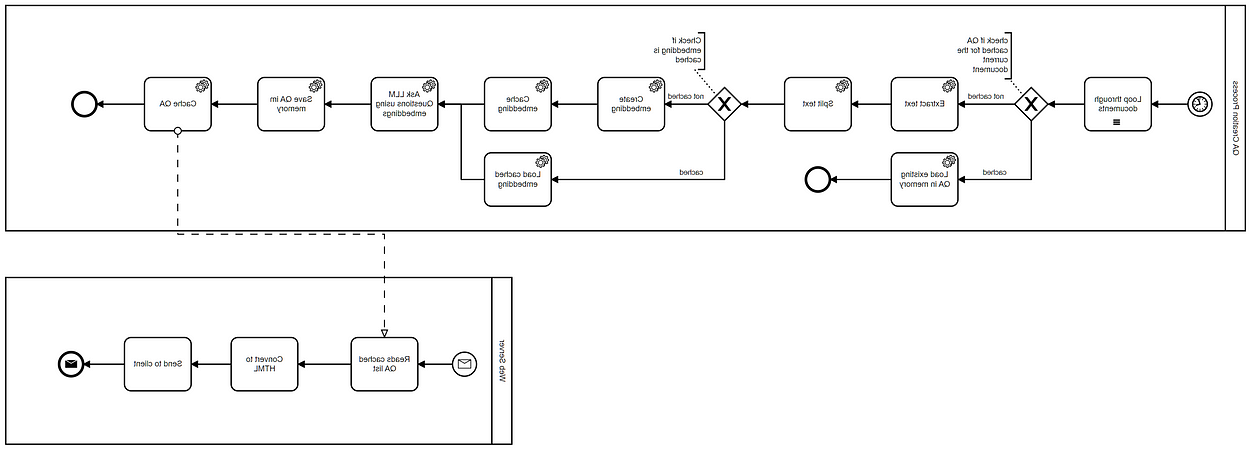
QA创建过程执行以下步骤:
- It loops all documents in a pre-defined folder (only pdf and docx files)
- It checks whether the question-answers for a specific candidate have been previously cached or not.
- If the question-answers were previously cached, then they get loaded into memory
- In case the QA’s were not cached, the text gets extracted and split.
- 工作流检查是否有任何缓存的嵌入.
- If there are cached embeddings then they are loaded into memory.
- If not ChatGPT is queried and a set of embeddings for the extracted text is retrieved
- 的 embeddings set are saved in a local directory and, thus cached.
- 使用嵌入集查询ChatGPT的所有答案.
- QA存储在内存中并缓存在文件系统中.
要了解什么是嵌入,请访问 OpenAI全球最大的博彩平台嵌入的页面.
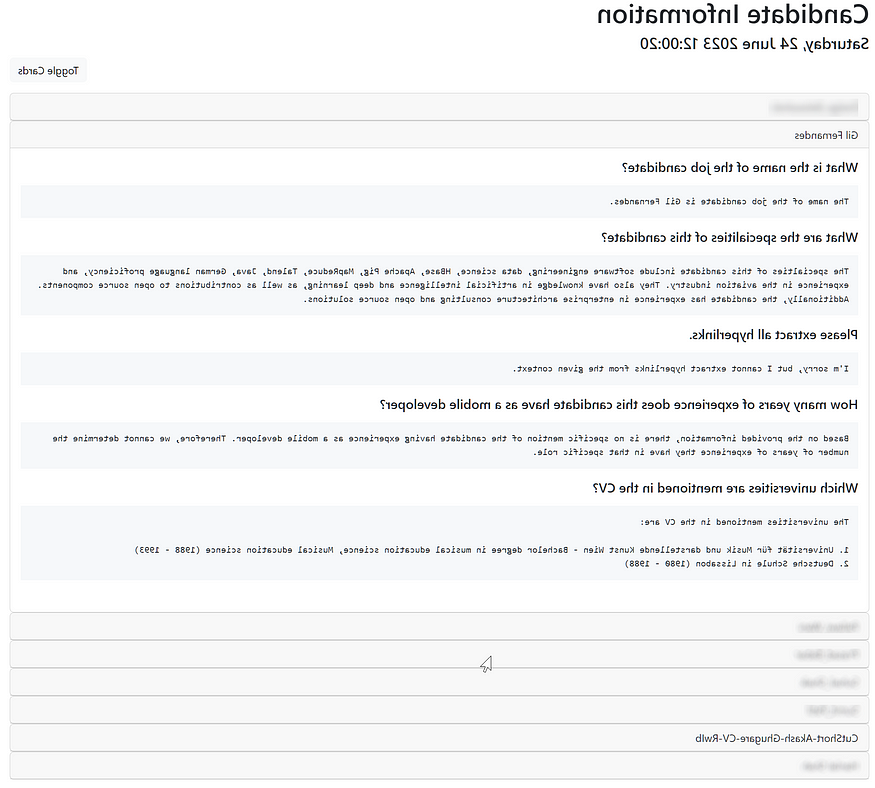
用户界面
的 user interface of this application is a single page that displays expandable cards with the QA’s related to a user:
设置和执行
的 implementation of the flow described above can be found in this GitHub repository:
GitHub - gilfernandes/document_stuff_playground: Playground project used to explore Lang链's…
Playground project used to explore Lang链's Document 的东西ing with question answering - GitHub …
实现
我们提到web应用程序有两个流. 实现有两个部分: 问题/答案创建过程 web服务器:
问题/答案创建过程
document_stuff_playground / document_extract.main·gilfernandes/document_stuff_playground
Playground project used to explore Lang链's Document 的东西ing with question answering …
我们使用了“gpt-3”.5-turbo-16k”模型以及OpenAI嵌入.
类配置():
模型= 'gpt-3.5-turbo-16k”
llm = ChatOpenAI(model=model, temperature=0)
embeddings = OpenAIEmbeddings()
Chunk_size = 2000
Chroma_persist_directory = 'chroma_store'
candidate_infos_cache = Path('candidate_infos_cache')
如果不是,candidate_infos_cache.存在():
candidate_infos_cache.mkdir ()We define a data class to contain the name of the file and the question/answer pairs:
@dataclass
类CandidateInfo ():
candidate_file: str
问题:list[(str, str)]的 function does the bulk of the work and loops through the files, 提取它们的内容, 创建嵌入, 创建答案并收集结果如下:
def extract_candidate_infos(doc_folder: Path) -> List[CandidateInfo]:
"""
Extracts the questions and answers from each pdf or docx file in `doc_folder`
并将它们保存在一个列表中. 首先,它循环遍历文件,提取其内容
as embeddings and caches these and then interacts with ChatGPT. 答案是
保存在数据结构中并缓存. 如果答案已经提供给候选人
它们是从泡菜文件中读取的.
:param doc_folder存放候选文档的文件夹.
:返回候选问题和答案的列表.
"""
如果不是doc_folder.存在():
“候选文件夹{doc_folder}不存在。!")
返回[]
candidate_list: list[CandidateInfo] = []
扩展:list[str] = ['**/*.pdf”、“* * / *.多克斯']
对于extensions中的extension:
对于doc_folder中的doc.rglob(扩展):
File_key = doc.阀杆
Cached_candidate_info = read_saved_candidate_info (file_key)
如果cached_candidate_info为None:
Docsearch = process_document(doc)
打印(f“加工{医生}”)
如果docsearch不是None:
qa = RetrievalQA.from_链_type (llm = cfg.Llm, 链_type=“stuff”,retriver =docsearch.as_retriever ())
Question_list = []
对于问题中的问题:
#在这里问问题
question_list.追加(问题,qa.运行(问题)))
candidate_info = CandidateInfo(candidate_file=file_key, questions=question_list)
write_candidate_infos (file_key candidate_info)
candidate_list.追加(candidate_info)
其他:
print(f"无法从{doc}检索内容")
其他:
candidate_list.追加(cached_candidate_info)
返回candidate_list我们还缓存了结果,以防止太多的API调用.
We have a function which 泡菜s (serializes) the collected results:
Def write_candidate_info (file_key, candidate_info):
Cached_file = CFG.candidate_infos_cache / file_key
使用open(cached_file, "wb")作为f:
泡菜.转储(candidate_info f)And another one which checks if the CV file already has corresponding QA’s on the local file sy阀杆:
def read_saved_candidate_infos(file_key: str) -> Union[None, CandidateInfo]:
Cached_file = CFG.candidate_infos_cache / file_key
试一试:
如果cached_file.存在():
使用open(cached_file, "rb")作为f:
返回泡菜.负载(f)
例外情况如下:
print(f"无法处理{file_key}")
回来没有的 function below extracts and persists embeddings on the local file sy阀杆:
def extract_embeddings(texts: List[Document], doc_path: Path) -> Chroma:
"""
Either saves the Chroma embeddings locally or reads them from disk, in case they exist.
:返回嵌入周围的色度包装器.
"""
Embedding_dir = f"{cfg.chroma_persist_directory} / {doc_path.茎}”
如果路径(embedding_dir).存在():
return Chroma(persist_directory=embedding_dir, embedding_function=cfg.嵌入的)
试一试:
docsearch =色度.from_documents(文本,cfg.嵌入,persist_directory = embedding_dir)
docsearch.persist ()
例外情况如下:
print(f"Failed to process {doc_path}: {str(e)}")
回来没有
返回docsearch我们正在使用 Chroma,一个开源嵌入 这里的数据库. Chroma allows to save embeddings (numerical vectors representing tokens) and their metadata.
这个函数读取文档并提取文本:
def process_document(doc_path) -> Chroma:
"""
通过从文档中加载文本来处理文档.
它支持两种格式:pdf和docx. 然后分裂
the text in large chunks from which then embeddings are extracted.
:param doc_path a path with documents or a string representing that path.
:返回嵌入周围的色度包装器.
"""
如果不是isinstance(doc_path, Path):
doc_path =路径(doc_path)
如果不是doc_path.存在():
print(f"文档({doc_path})不存在. 请检查”)
其他:
打印(f”处理{doc_path}”)
(PDFPlumberLoader(str(doc_path)).后缀== ".pdf”
其他Docx2txtLoader (str (doc_path)))
doc_list: List[Document] = loader.load ()
print(f"已提取的文档:{len(doc_list)}")
对于i, doc在enumerate(doc_list)中:
i += 1
如果len(医生.Page_content) == 0
print(f"文档有空页:{i}")
其他:
打印(f"页{i}的长度:{len(doc.page_content)}”)
text_splitter = CharacterTextSplitter(chunk_size=cfg).chunk_size chunk_overlap = 0)
文本= text_splitter.split_documents (doc_list)
返回extract_embeddings(文本,doc_path)Web服务器
This part of the implementation serves the results which are stored in memory using the FastAPI 框架. You could also just create a REST service and develop an application with a modern web 框架.
Our implementation uses a scheduled background thread to update the list of QAs about the candidates in case CVs are saved in the input directory:
类CandidateCache ():
candidate_info_html = "Processing, please wait ...
"
candidate_cache = CandidateCache()
Sleep_time = 60 * 10
类BackgroundTasks(线程.线程):
"""
在后台处理文档和查询聊天GPT.
"""
def __init__(自我, candidate_cache: CandidateCache, sleep_time = SLEEP_TIME):
super ().__init__ ()
自我.candidate_cache,自我.Sleep_time = candidate_cache, Sleep_time
自我.data_cache = sleep_time的n You can then find an HTML-generating endpoint that renders a simple page:
@app.get(" /候选人.html”,response_class = HTMLResponse)
Async def hello_html():
def generate_timestamp ():
#获取当前日期和时间
Now =日期时间.现在()
#获取英文的周、日、月、年和时间
工作日=现在.strftime(“%”)
日=现在.strftime(“% d”)
月=现在.strftime(“% B”)
年=现在.Y strftime(“%”)
时间=现在.strftime(“% H: % M: % S”)
#创建时间戳字符串
时间戳= f"{星期},{日}{月}{年}{时间}"
返回时间戳
返回f”“”
服务器通过 uvicorn:
如果__name__ == '__main__':
print(“快速API设置”)
uvicorn.运行(应用程序、主机= " 0.0.0.0”,端口= 8000)结论
It is relatively easy to build a basic human resources application based on documents with LangChain 使用法学硕士来回答有关这些文档的问题. Much of the heavy lifting (communication with LLM, embeddings generation) is done by LangChain,它也为不同的文件类型提供广泛的支持.
For human resources, you could also create an application which ranks candidates with the 地图排名 链. LangChain would also support such functionality, but we will explore that in subsequent blogs.